近期实践了高并发场景下,如何去实现抢购系统的研究。虽然方案并不算成功,但是本次能将以往只在资料中学习过的知识付诸于现实,也让自己畅快淋漓了一番。本篇文章所阐述的内容都比较基础,重在于将实践过程中所得到的经验和教训分享出来给大家。
以下将分为五个方面来回顾下本次高并发的实践经历。
- 1.抢购场景特点
- 2.技术选型
- 3.方案思路
- 4.优劣势辨析
- 5.小结一下
一、抢购场景的特点
在日常生活中,电子商务营销手段中,抢购、促销是最为常用的提高销售的手段。最熟悉不过的当然就是天猫“双十一”购物节了。既然是“抢购”,用通俗的话来概括,那就是手快有手慢无。以下我们做了一些细分:
1.1 限时限量
- 限用户样本
- 限用户可购买量
- 限商品总量
- 限抢购时间
1.2 防伪防恶意
- 防虚假用户购买
- 防恶意系统攻击
而广大群众并不一定都跟着你的步伐走,可能他们会跟抢12306火车票的手段一样,在你的抢购活动中付诸于实践,往往这个会给系统带来四面楚歌般的无形压力,轻者响应延迟,重者宕机。
写到这里,复杂度已经可见一斑,内容涉及了各个方面,例如并发编程、安全、缓存、关系型数据存储、网络流量、防火墙、服务容器、连接池、IO通信。虽说内容很多,但是我们可以从中根据自己所面临的场景,选择其中一些合适的技术手段即可,不必面面俱到追求完美,它们都只是你实现目标的工具。
二、技术选型
了解基本的抢购场景知识之后,就是考虑怎么去解决场景中所遇到的实际问题了。对于抢购场景的特点,我们给每个特点归归类:
- 限用户样本、限抢购时间,这2项可以算是参加抢购的前置条件,不满足则拒绝请求。
对于用户样本的限定,普通的条件性编码可以满足这项需要,因为这项属于前置条件,条件数据的属性当确定活动用户样本之后,它们就成为了静态数据,没有并发的意外风险。
对于抢购时间,这项条件可以借鉴业界对这方面的设计思路,将静态代码(html等静态页面内容)部署到CDN节点上,而仅保留一项js文件(该文件中包含了判断抢购开始的请求编码,当然里面可以包含一项随机token来保障代码所发出的请求的有效性)执行动态加载,以保障抢购可以准时开始。
对于抢购页面CDN静态之后所出现的无效点击、提前知道抢购页面等问题,这部分可以使用包含随机token串的页面url,用以保证抢购页面的有效性和请求的合法性。
- 限用户可购买量、限商品总量,这2项是整个抢购场景中的核心前提,即“不可超售”的业务特点。
对于用户可购买量、商品总量的限制,这部分可以考虑使用编程锁的实现,如果考虑到多机部署的分布式需要,可以考虑使用分布式锁,同时加以“分而治之”的思路,可以提高请求的并发量。
关于锁的知识,我们常见的锁有悲观锁和乐观锁,而锁的实现方式可以是中间件、缓存、JDK自带同步锁、关系型数据库等方式。
- 防虚假用户购买,这一特点旨在于系统如何去辨析真正的消费用户,而非临时创建的僵尸用户。
这部分比较难以实现,并不是简单的判别某个单位时间同一来源请求上限值、验证码校验这么一些常见的指标。如果要根本性解决这方面,可能需要使用一些机器学习方面的知识,分析出那类请求可以判别为“疑似攻击”,同时还需要准确率,这是一门深奥的学问,目前自己还没有太多的涉及就不深入谈论了。
- 防恶意系统攻击,这项属于系统部署层面上需要考量的架构问题。如若不能及时识别出这是一次攻击而非正常消费请求,那么系统会面临宕机的风险。
关于恶意系统攻击,与前面谈及的“防虚假用户购买”有相同之处,“虚假用户购买”的量达到了一定的阈值,那么就可以归类为“恶意系统攻击”了。在WEB安全领域上,有许多常见的网络攻击都是需要去规避和解决的,无论是编码上还是运维部署层面上,例如DDoS、SQL注入、信息伪造等手段。
本次实践过程中,对于这一块并没有太多的涉及,只是通过一些流量设置上的控制,避免了服务容器由于请求压力过高而产生的宕机风险。这一块待日后自己的知识库成熟之后,再po文分享下自己的实践感触。
三、方案思路
3.1 基本思路和考量点
- 不可超售,需要使用到线程安全、线程锁、本地线程、事务性、原子CAS特性、阻塞/非阻塞队列等知识;
- 分而治之,将商品可销售总量分为多条管道同时进行销售,由负载均衡算法代理路由的逻辑;
- 存储介质上,考量可持久化缓存、关系型数据库;
- 在组件的配置方面,考量服务容器的并行连接池配置、缓存的连接池配置、关系型数据库连接池配置、编码线程池配置、JVM启动参数(例如JVM PermSize、Xms、Xmx内存项配置);
- 在流程实现上,将一些有效判断节点分布在真实消费商品的逻辑之前,提高核心逻辑的有效执行占比,提高访问效率;
- 在消费数据的持久化措施上,采用“生产者-消费者”的队列实现模式,异步的策略将消费数据尽可能快地持久化到日常使用的关系型数据库中,便于查看和其他业务系统的接口读取;
3.2 逻辑流程图
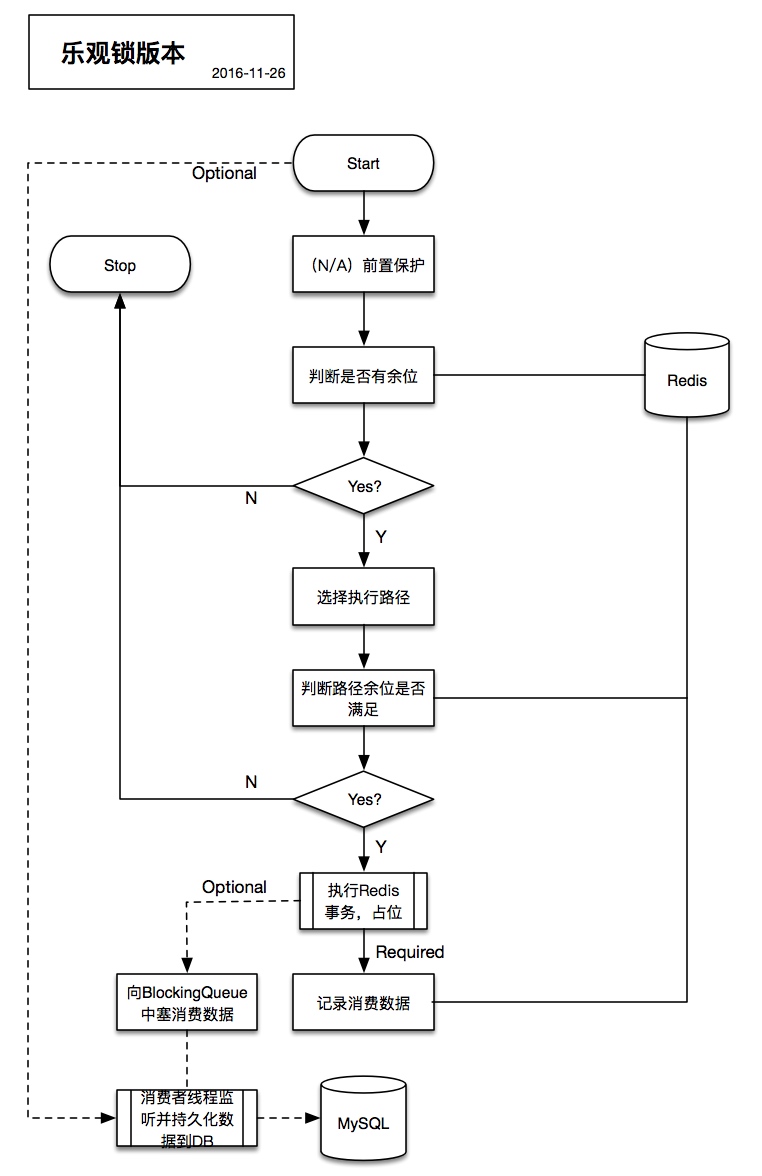
3.3 实现过程中可能需要额外关注的部分
Redis使用方面
- 1.系统Redis的连接池配置,最大可用连接
maxTotal要小于Redis服务配置redis.conf中maxclients数值; - 2.系统Redis的连接超时时长
maxWaitMillis要尽可能地根据系统可承载压力进行设置,一般不可超过5s,高并发的场景下建议在2s以下; - 3.为保障系统Redis客户端从池子中获取的连接不是broken的,参数
testOnBorrow => true一定要加上; - 4.Jedis连接池的空闲释放算法采用的是apache common pool作的实现,GenericObjectPool是通过“驱逐者线程Evictor”管理“空闲池对象”的。在高并发场景下,选用
LIFO可以更快地通过Evictor驱逐者任务将空闲无占用连接及时释放掉,而避免采用FIFO致使部分idle连接处在starvation状态下久久得不到释放,从而造成leaks of redis resources; - 5.如果你使用的不是Spring框架对Redis客户端进行
scope="singleton"的集成,那么在创建连接池之时,也需要避免瞬间并发而导致的池子被多建的场景发生,因为每一个池子都会由于配置minIdle而固定占用着redis的连接数量; - 6.如果你使用的是分布式集群Redis,那么可以对连接池配置多机,如此可有效提高连接数和Redis服务性能;
- 7.如果你使用的是Spring+Jedis(注:最受欢迎的Redis Client之一)的Redis编码方案,请留意
ShardedJedisPool和JedisPool的区别,后者所取得的连接可以执行事务、多key批量等操作,而前者是为Redis分布式集群而生,每一次所获取的连接并不保证相同和唯一来源;
这里给出一个简单的Spring+Jedis的连接池配置例子:
- Jedis连接池基础参数配置
1 | <bean id="jedisConfig" class="redis.clients.jedis.JedisPoolConfig"> |
- ShardedJedisPool连接池
1 | <bean id="shardedJedisPool" class="redis.clients.jedis.ShardedJedisPool" scope="singleton"> |
- JedisPool连接池
1 | <bean id="jedisPool" class="redis.clients.jedis.JedisPool" scope="singleton"> |
服务容器的运行保障方面(本次所使用到的是Tomcat)
为了降低服务容器因为过载而造成的请求堵塞、容器停滞、宕机等风险,针对Tomcat的连接数方面做了些配置上的调整,以确保可控可监听:
- Tomcat Executor连接线程池
1 | <Executor name="tomcatThreadPool" // 线程池名称 |
- Tomcat Connector连接配置
1 | <Connector executor="tomcatThreadPool" // 线程池引用 |
与此同时,我们还对服务容器所占用的内存空间进行了分配和调整:
- Tomcat Startup Properties启动参数
1 | # Configurations of JVM properties. |
在实践过程中发现,单个Tomcat实例在并行负载线程达到>3000之时,会使用到acceptCount所设置的数值创建队列,将后进的线程排队到该队列内。
但是同时也发现,当并行负载线程>3000之后,CPU和Head占用会大幅升高,响应时长也在爬高并超过实践过程中预设的1s(注:低负载情况下请求响应总时长为200-300ms);
当并行负载线程>5000之后,Tocmat发生了假死状况(注:这里所说的假死,是处于一种Tomcat进程仍然存活,但是请求已不再执行和处理),Heap内存下降,CPU下降,此时的Tomcat其实已经和宕机无异。这些情况所发生的原因,其中有一点毋庸置疑的那就是,你增加Tomcat准入线程数的同时,也在增加CPU对于容器上下文切换频率,就会增加CPU的资源消耗,自然地,请求的响应时间也就越来越慢。所以一个合理的线程连接数是如此的关键。
根据网络查询资料,许多IT从业者给出了近似的一些结论:如果需要考虑Tomcat在支撑并发数>1000以上,则可以引入分布式方案了。确实,系统稳定性是非常重要的。
四、优劣势辨析
本次实践过程中采用的是“分布式事务 + CAS原子性操作函数”所实现的乐观锁解决方案。在阐述其中优劣势之前,我们先来了解下关于抢购系统的外观设计办法有哪些。
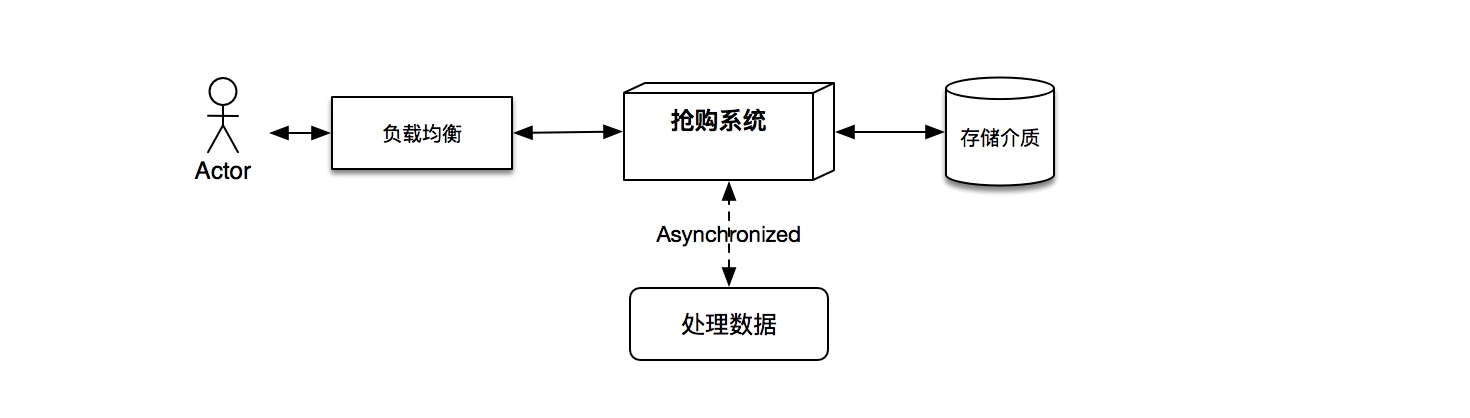
- 方案一:抢购结果滞后反馈
这一方案很典型地采用了异步处理的机制,虽然可以很大层面上解决访问压力的问题,但是会给人一种“暗箱操作”、“用户体验极其不好”的感觉。如下图所示:
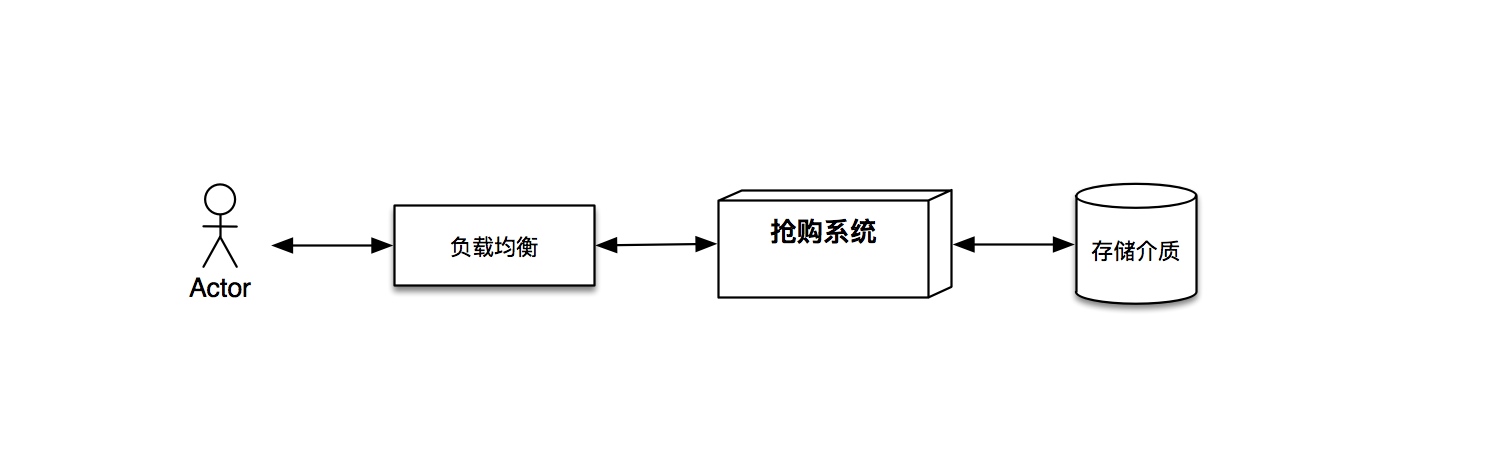
- 方案二:抢购结果即刻响应
如方案标题所阐述的那样,即刻给用户反馈抢购操作的结果。该方案有很好的用户体验,但是对于系统也同样有着很高的考验。例如如何杜绝商品超售超发等问题的发生,因为一旦发生了超售超发,也就意味着系统的问题正在引发经济上的亏损。
本次实践中采用的是方案二的做法,如文章前面所述的流程图一样,采用的是乐观锁的实现思路。那么相对应的是否还有其他的实现思路,同样可以实现方案二呢?毋庸置疑,当然是有的。
- 思路一:悲观锁思路
这里无论你采用的是分布式锁(Distributed lock)还是监视器锁(Monitor lock),他们有一个共通的特点,那就是Mutex(互斥性)。在同一时间只允许一个访问者可以访问共享资源,其他访问者必须等到加锁的访问者释放锁之后才可进入临界区进行资源访问。
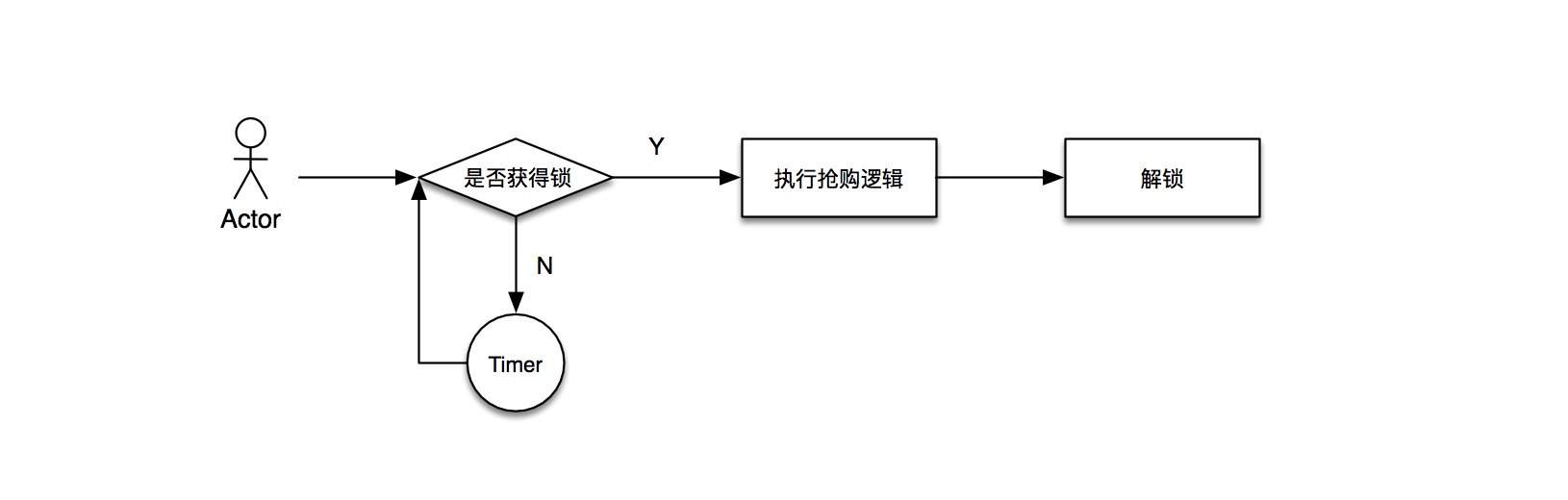
在上图形势下,当并发请求上升之时,每个请求都需要请求锁,而线程之间也存在着线程调度的情况,自然也会出现starvation的现象发生,驻留了很多优先级低的线程资源未能及时处理和释放。随着并发时间的流逝,服务容器一定会出现请求阻塞,响应时间延迟,容器资源占用率高,Heap内存溢出等问题的发生。
- 思路二:队列的思路
如果你对JDK中并发包有一定了解,这一思路一定非常熟悉,就是在阻塞性队列实现过程中,常常所需要用到的“生产者-消费者”的并发设计模式。
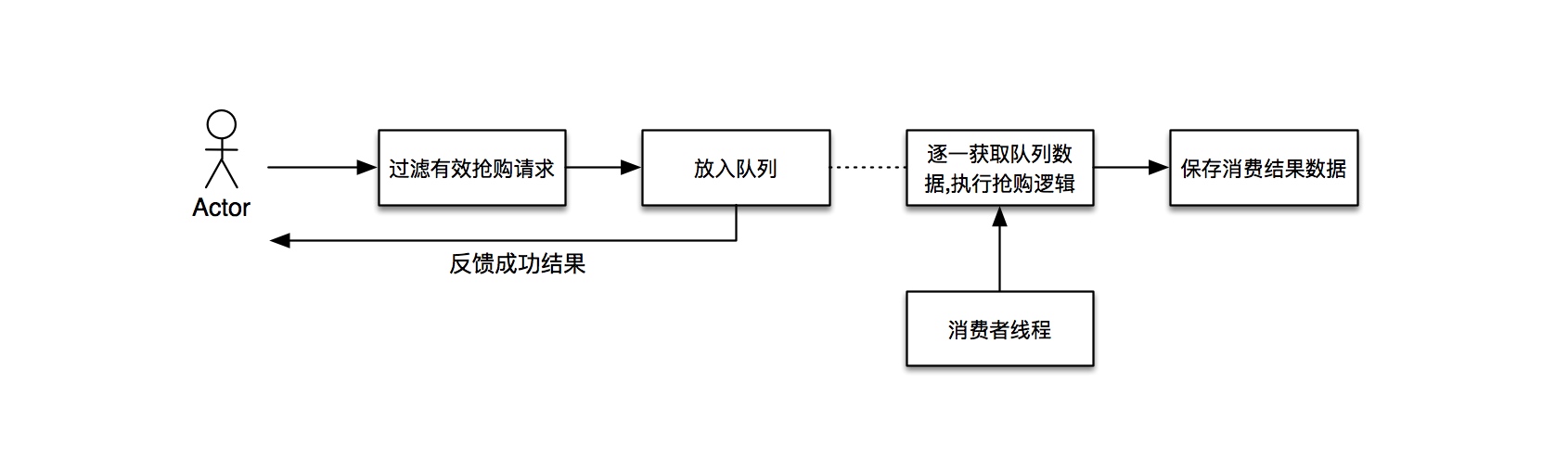
如图,这一思路优势是可以很快地处理并响应用户的抢购请求,只需要执行一些必要的过滤逻辑即可,舍去了关系型存储和其他存储的连接资源的请求和读写。劣势当然是有的,它过度依赖队列驻留在内存中的数据,一旦tomcat发生阻塞或者宕机,那么数据将永久丢失,这是灾难性的结果。另外,我们所应对的是并发的场景,队列的长度虽然可以设置为无上限,但是服务容器的资源是有限的,当消费速度小于请求速度之时,系统就逐渐迈向queue内存溢出的悬崖。
- 思路三:乐观锁思路
本次实践的正是乐观锁思路。所谓乐观,自然与悲观的理念是相反的。悲观的思路会将访问线程用锁这一介质的作用,使得线程进入阻塞和等待。乐观的思路,就是临界区的共享资源不需要锁的介入就可以随意访问和修改,没有任何阻塞性质的限定。在并发级别的分类当中,有一种并发的级别叫做“无等待”,这是终极乐观锁的一种体现。
基本实现流程如下图所示:
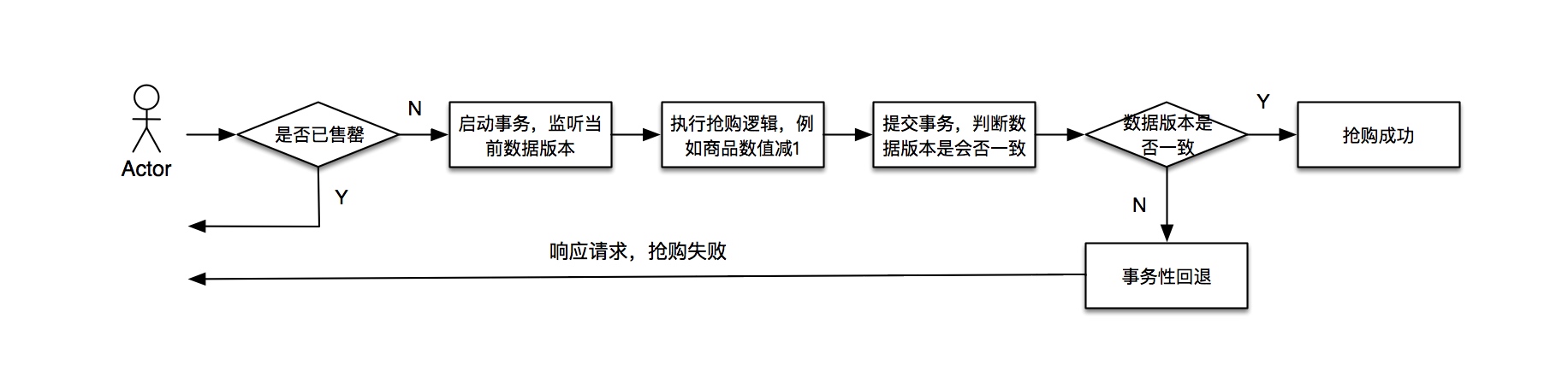
很显然,乐观锁的思路,是一种无锁无等待的一种并发实现方式。可以使用事务CAS原子的特性来保障数据的准确性,避免了“超售超发”的问题发生。可以在请求线程并发过程中,无阻塞地进行抢购逻辑的处理。但是,与此同时引入了另外一个问题,它不可避免的会出现操作被事务性回退的现象,放在抢购场景下解释,就是一个请求进入事务之时,数据的无误可占用和消费的,但是当线程执行到提交事务一步时,数据版本出现了不一致(也就是其他的线程将商品占用并成功提交了事务),从而被定性为该请求抢购失败,即无效抢购。
和前面所提及的队列的思路比较起来,乐观锁的思路所实现的结果是无序的。假设你需要去保证按时序进行分配抢购的产品,那么乐观锁并不适合这一诉求,有序队列的实现思路可能更为合适。
五、小结一下
似乎也不需要总结太多,上文已经把整个方案过程中所涉及的考量和技术点都一一覆盖到了,可能会有些片面,或者有些阐述地比较粗糙,但毕竟这是一篇分享实现思路的文章而并非技术方案细节的文档,所以可以根据上述思路自行发散,有所参考,有所改进。
如果你有更好的建议、方案或者是优化策略,不妨在留言板上写下你的想法。
六、参考资料
本篇文章有原创体会,也有网络资料参考,国内外均涉及,这里就不一一罗列了,可以自行根据“抢购”、“分布式锁(distributed lock)”、“高并发(concurrency/parallel computing)”、“阻塞队列(blocking queue)”等关键词进行检索和进一步学习。
在此感谢伟大的Tim Berners-Lee、RMS(Richard Matthew Stallman)等业界大神,给世界带来了互联网,创造了开源的氛围和精神,让我们的信息得以共享。